2018-8-31 seo達人
如果您想訂閱本博客內容,每天自動發到您的郵箱中, 請點這里
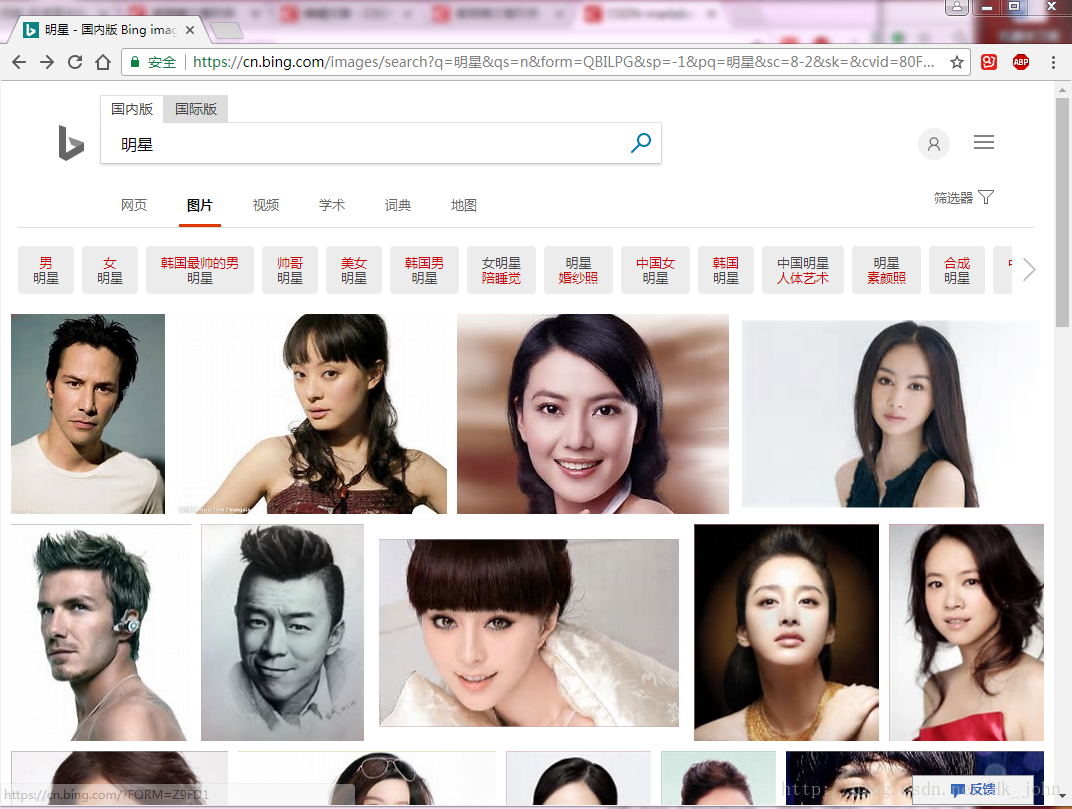
圖片三個網站的圖片搜索結果進行爬取和下載。
首先通過爬蟲過程中遇到的問題,總結如下:
1、一次頁面加載的圖片數量各個網站是不定的,每翻一頁就會刷新一次,對于數據量大的爬蟲幾乎都需要用到翻頁功能,有如下兩種方式:
1)通過網站上的網址進行刷新,例如必應圖片:
2)通過selenium來實現模擬鼠標操作來進行翻頁,這一點會在Google圖片爬取的時候進行講解。
2、每個網站應用的圖片加載技術都不一樣,對于靜態加載的網站爬取圖片非常容易,因為每張圖片的url都直接顯示在網頁源碼中,找到每張圖片對應的url即可使用urlretrieve()進行下載。然而對于動態加載的網站就比較復雜,需要具體問題具體分析,例如google圖片每次就會加載35張圖片(只能得到35張圖片的url),當滾動一次后網頁并不刷新但是會再次加載一批圖片,與前面加載完成的都一起顯示在網頁源碼中。對于動態加載的網站我推薦使用selenium庫來爬取。
對于爬取圖片的流程基本如下(對于可以通過網址實現翻頁或者無需翻頁的網站):
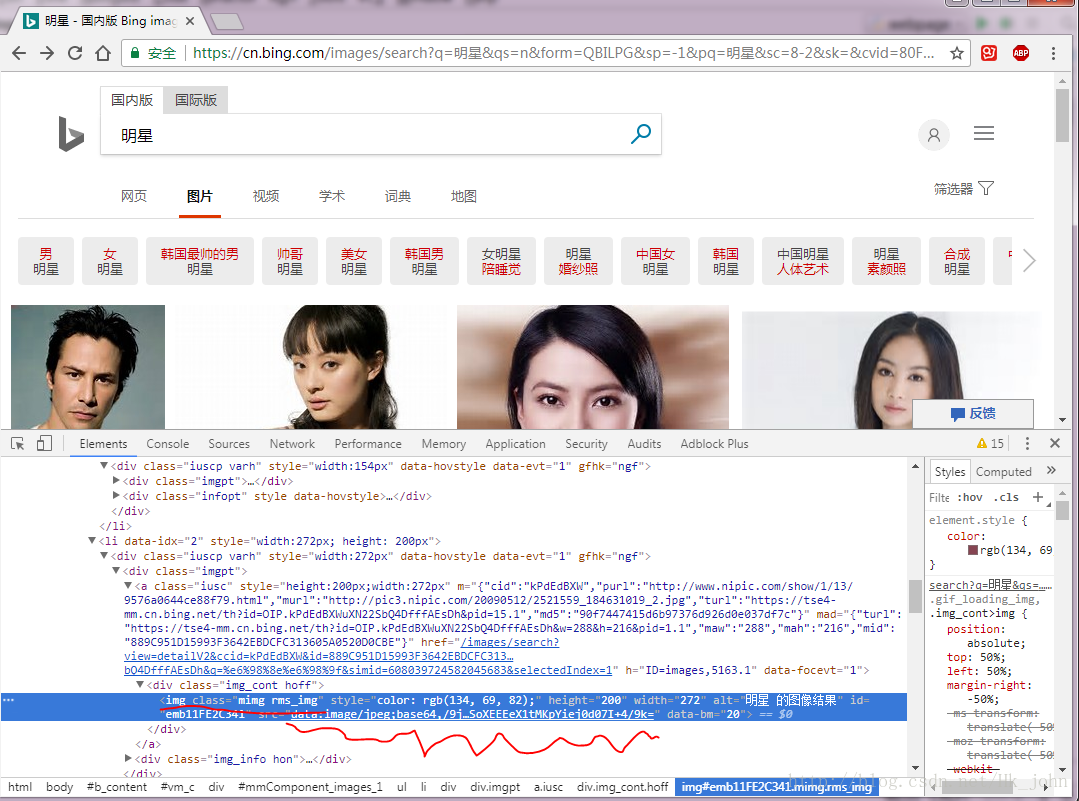
1. 找到你需要爬取圖片的網站。(以必應為例)
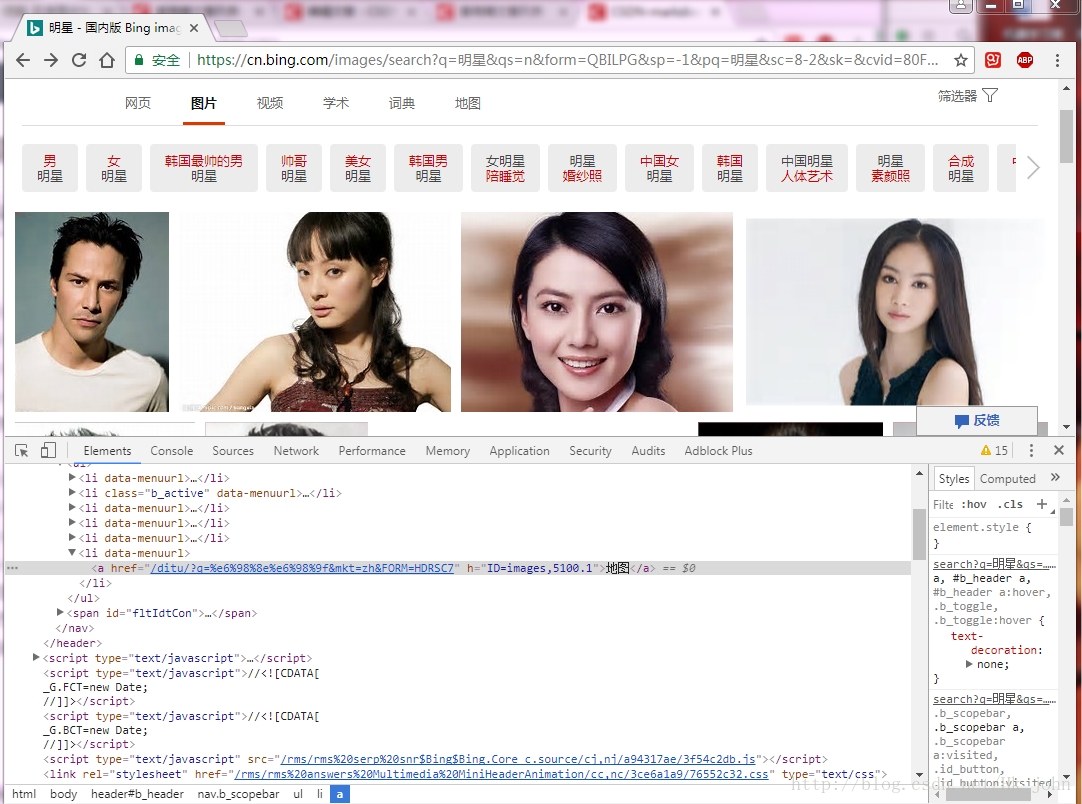
2. 使用google元素檢查(其他的沒用過不做介紹)來查看網頁源碼。
3. 使用左上角的元素檢查來找到對應圖片的代碼。
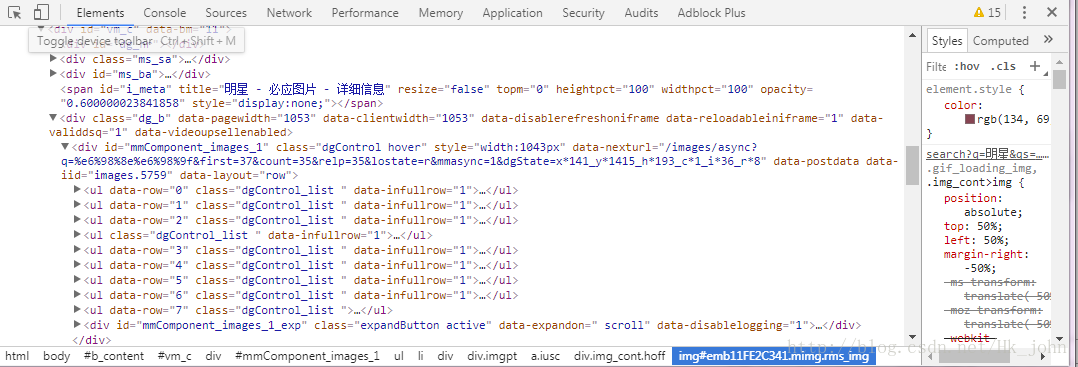
4. 通過觀察找到翻頁的規律(有些網站的動態加載是完全看不出來的,這種方法不推薦)
從圖中可以看到標簽div,class=’dgControl hover’中的data-nexturl的內容隨著我們滾動頁面翻頁first會一直改變,q=二進制碼即我們關鍵字的二進制表示形式。加上前綴之后由此我們才得到了我們要用的url。
5. 我們將網頁的源碼放進BeautifulSoup中,代碼如下:
我們得到的soup是一個class ‘bs4.BeautifulSoup’對象,可以直接對其進行操作,具體內容自行查找。
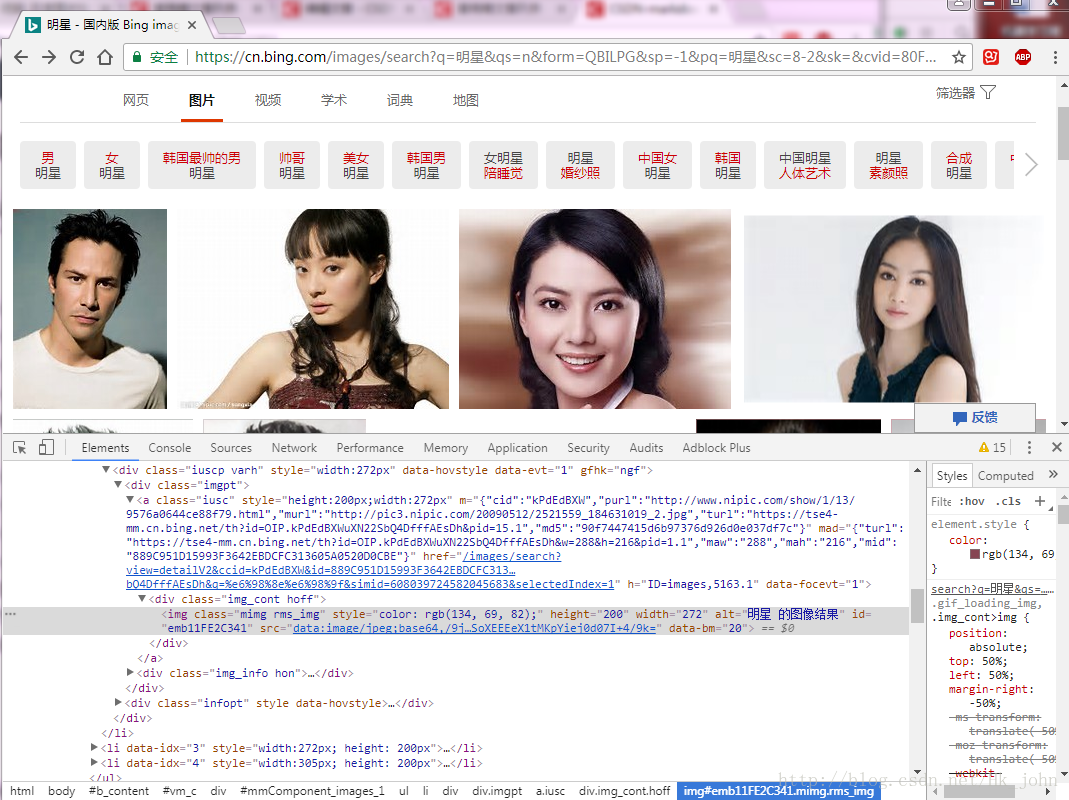
首先選取我們需要的url所在的class,如下圖:
波浪線是我們需要的url。
我們由下面的代碼得到我們需要的url:
最后調用urlretrieve()函數下載我們得到的圖片url,代碼如下:
這里需要強調是像前面的打開網址和現在的下載圖片都需要使用try except進行錯誤測試,否則出錯時程序很容易崩潰,大大浪費了數據采集的時間。
以上就是對單個頁面進行數據采集的流程,緊接著改變url中{1}進行翻頁操作繼續采集下一頁。
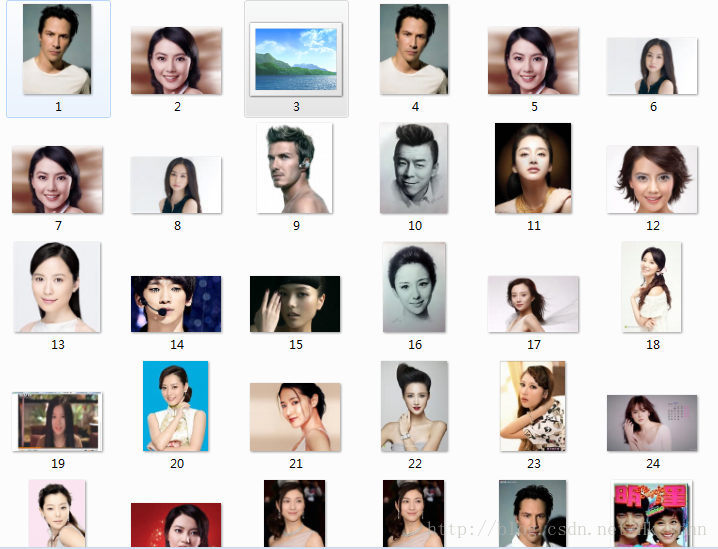
數據采集結果如下:
有問題請留言。
藍藍設計( www.dzxscac.cn )是一家專注而深入的界面設計公司,為期望卓越的國內外企業提供卓越的UI界面設計、BS界面設計 、 cs界面設計 、 ipad界面設計 、 包裝設計 、 圖標定制 、 用戶體驗 、交互設計、 網站建設 、平面設計服務。